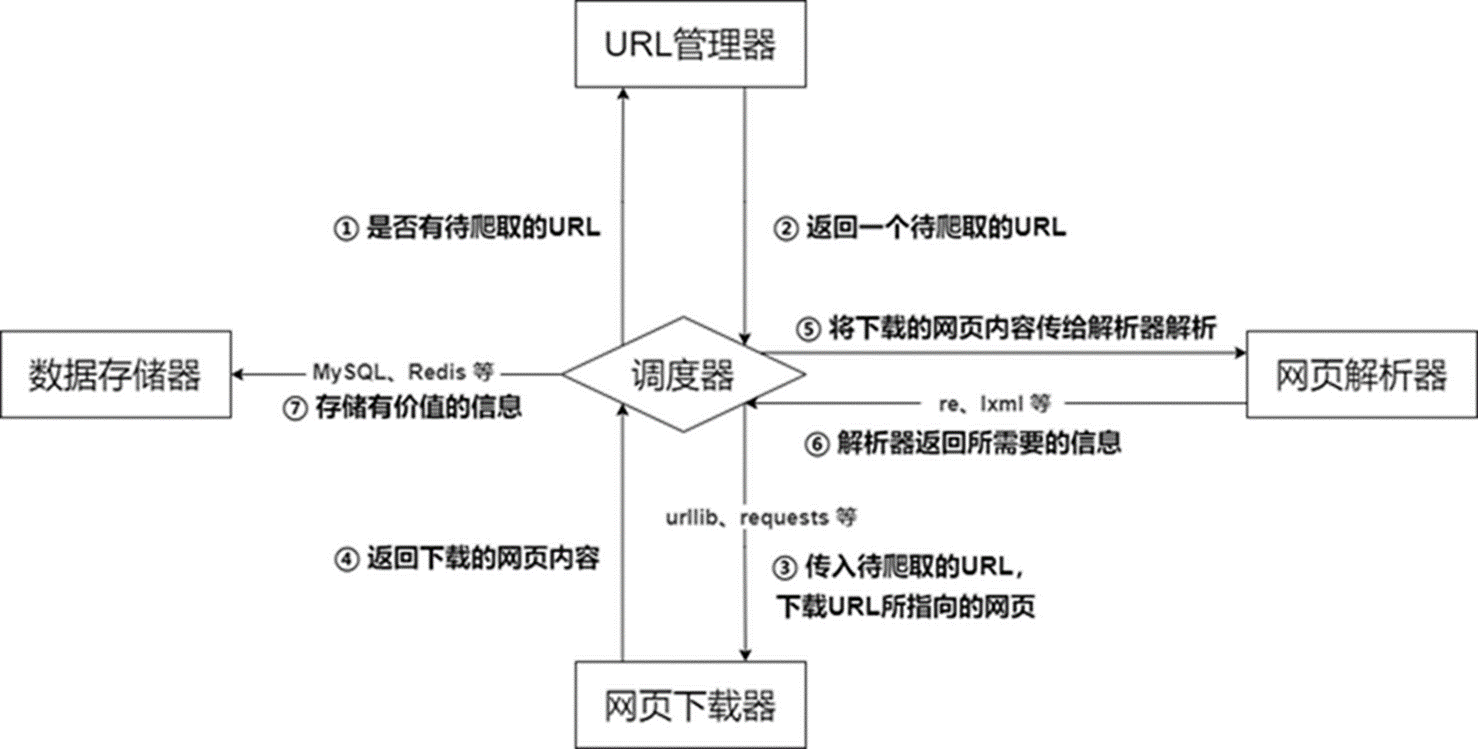
爬虫的基本流程和基本架构
一、爬虫的基本流程
(1) 发起请求:通过 URL 向服务器发起 Request 请求(同打开浏览器,输入网址浏览网页),请求可以包含额外的 headers、cookies、proxies、data 等信息,Python 提供了许多库,帮助我们实现这个流程,完成 HTTP 请求操作,如 urllib、requests 等;
(2) 获取响应内容:如果服务器正常响应,会接收到 Response,Response 即为我们所请求的网页内容,包含 HTML(网页源代码),JSON 数据或者二进制的数据(视频、音频、图片)等;
(3) 解析内容:接收到响应内容后,需要对其进行解析,提取数据内容,如果是 HTML(网页源代码),则可以使用网页解析器进行解析,如正则表达式(re)、Beautiful Soup、pyquery、lxml 等;如果是 JSON 数据,则可以转换成 JSON 对象进行解析;如果是二进制的数据,则可以保存到文件进行进一步处理;
(4) 保存数据:可以保存到本地文件(txt、json、csv 等),或者保存到数据库(MySQL,Redis,MongoDB 等),也可以保存至远程服务器,如借助 SFTP 进行操作等。
二、爬虫的基本架构
爬虫的基本架构主要由五个部分组成,分别是爬虫调度器、URL 管理器、网页下载器、网页解析器、信息采集器:
(1) 爬虫调度器:相当于一台电脑的 CPU,主要负责调度 URL 管理器、下载器、解析器之间的协调工作,用于各个模块之间的通信,可以理解为爬虫的入口与核心,爬虫的执行策略在此模块进行定义;
(2) URL 管理器:包括待爬取的 URL 地址和已爬取的 URL 地址,防止重复抓取 URL 和循环抓取 URL,实现 URL 管理器主要用三种方式,通过内存、数据库、缓存数据库来实现;
(3) 网页下载器:负责通过 URL 将网页进行下载,主要是进行相应的伪装处理模拟浏览器访问、下载网页,常用库为 urllib、requests 等;
(4) 网页解析器:负责对网页信息进行解析,可以按照要求提取出有用的信息,也可以根据 DOM 树的解析方式来解析。如正则表达式(re)、Beautiful Soup、pyquery、lxml 等,根据实际情况灵活使用;
(5) 数据存储器:负责将解析后的信息进行存储、显示等数据处理。